"Being able to deploy computing power according to our needs and benefiting from a very practical API is what seduced us. And last but not least, the fact that it reduces the carbon footprint of computation."
Olivier Oldrini · Co-Founder and President

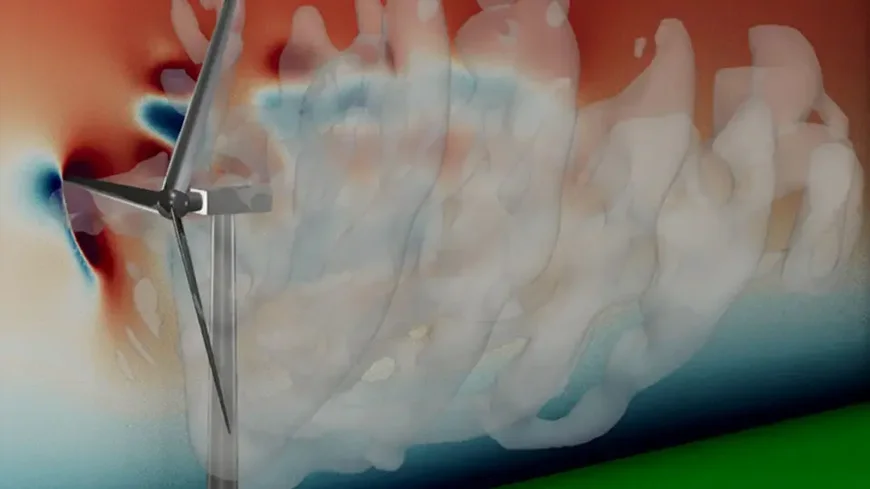
At AmpliSIM, we are convinced that when it comes to the environment, well-informed people make better decisions. We have therefore developed a web platform to quickly and simply model the impact on the environment, such as air. We help local authorities, engineering offices and industrialists to map and predict the impact of their activity on air quality.
To be able to map and forecast, you need to use modeling and simulation tools that are generally complex and slow to implement and that are very data-intensive. We make these tools much more accessible and easier to use. This allows us to internalize part of the expertise and to be able to compare development scenarios in terms of impact on air quality, for example, simply and quickly.
In the environmental field, a lot of data is needed. And these data have to be found from external sources.
For example, when SONY tries to determine the resistance of a telephone case, all the data is known: the dimensions, the material, etc. We enter it into the computer and see, via simulation, if it breaks when I drop it on the floor, or when I bend it. In the environment, it is exactly the opposite. The main part of the data is outside: we will need, for example, the topography (how high the ground rises or falls), the use of the ground (building, water, forest...), and the weather. And these data are retrieved from different actors in different formats, very heterogeneous. Being able to retrieve the right data, at the right scale and in the right place, is part of our job.
The volume of data varies according to the model we use. It can range from a few hundred kilobytes to several terabytes. The data can be small, but they are often in large numbers, or on the contrary, very massive. For example, it can be the wind and temperature parameters at a weather station for a certain period (3 years for example) with data every ten minutes. But it can also be the results of forecasting models from Météo France, i.e. models that work throughout Europe, therefore with large computing grids.
Our job at AmpliSIM is really to choose the data we use, the compute parameters, to be able to parallelize codes to get results more quickly. But our job is not at all to make computers, nor to maintain and deploy them. So what we looked for in Qarnot was above all the ability to deploy computers on the fly according to our needs, which fluctuate. Fluctuating because we have both compute that take place over long periods such as a few years, but also compute that will start systematically, every hour for example, to ensure the monitoring of industrial units. We re-calculate every hour in real-time from data measured on site. Being able to deploy computing power as needed and benefit from a very practical API is what appealed to us. And last but not least, it reduces the carbon footprint of compute. This was an important criterion for us who work in the environmental sector.
What we appreciated was the ability to use a Python SDK (the language we mainly use). This allowed us to immediately attack disks, deploy compute, specify things... It was naturally integrated into our workflow.
The API is very easy to access but the teams were also very responsive. We interacted a lot daily. For example, we hesitated between several workflows and very quickly, by discussing with the teams, we focused on one solution, which allowed us to save a lot of time. We are in a special case because we automate a lot, but the first deployment of the compute only took us a few weeks, whereas if we had used a standard architecture, it would have taken us a few months to implement.
In addition, the fact that the computing infrastructure is based in France and meets the most demanding security standards was a key point for a large number of our customers, in particular industrial companies and certain design offices.
.webp)